

在我们这个传播过度的社会里,最后的办法是传送极其简单的信息。
术语
分区:对应文件系统上用来存储数据位置,可以理解为机器上的一个盘符。
队列:作业管理系统把系统的计算资源划分到不同的集合,用户的作业可以提交到这些集合排队运行,称这些集合为队列。
目录
1. 系统资源简介
1.1 计算资源(节点配置)
1.2 存储资源(文件系统)
2. 使用系统应用软件
2.1 简介
2.2 基本命令
3. Slurm 作业管理系统
3.1 sinfo 查看系统资源
3.2 squeue 查看作业状态
3.3 srun 交互提交作业
3.4 sbatch 后台提交作业
3.5 salloc 分配模式作业提交
3.6 scancel 取消已提交的作业
3.7 scontrol 查看正在运行的作业信息
3.8 sacct 查看历史作业信息
4. 编译器
4.1 Intel 编译器
4.2 GCC编译器
4.3 MPI编译环境
1. 系统资源简介
1.1 计算资源(节点配置)
共享计算服务器系统的作业队列是 cpu64c 队列,通过 sinfo 可以查看队列情况,cpu64c 队列的节点配置是:Intel E5-2683v4@2.1GHz ,32G内存,64核,电信家庭WiFi5G光纤千兆网络。
1.2 存储资源(文件系统)
公用软件安装在文件系统 /opt 下,登录系统后通过 pwd 命令可以查看自己当前所在位置,无需 root 权限编译的软件或一些即取即用的脚本与小程序可以安装在自己用户目录下,大程序尽量在我协助下安装,切勿轻易删除文件避免重要文件缺失。使用脚本提交作业,每个新开的账号默认存储是 20G ,在家目录下执行 “df -h” 查看磁盘空间使用情况,执行 “du --max-depth=1 -h” 获取当前的文件夹下的磁盘使用情况,前 n-1 行是某文件夹下某个文件(夹)大小,最后一行是该目录总大小。应养成查看使用磁盘存储的习惯,用户数据占用的磁盘空间超过配额后会影响数据保存或者作业运行,建议经常检查并及时清理备份不需要的数据,如需要较大的磁盘空间存储数据,请联系我增加配额。
2. 使用系统应用软件
2.1 简介
由于目前服务器算力资源有限,也是自己用的多,故不安装更多的管理软件、美化工具等等,这样节省资源也省去折腾宝贵的浪费时间,很多软件都是CentOS系统自带的,比如 bash、vim等。
2.2 基本命令
常用命令如下:
| 命令 | 功能 | 例子 |
| apt-get | Debian、Ubuntu以及类似系统的ATP软件工具网络下载命令 | apt-get install package_name #安装/更新一个 deb 包 apt-get update #升级列表中的软件包 |
| awk | 文本数据处理,逐行扫描目标文字行并执行用户想要的处理 | awk '/^$/ {print "Blank line"}' test1.txt #/^$/是一个正则表达式,功能是匹配文本中的空白行,同时可以看到,执行命令使用的是 print 命令,此命令经常会使用,它的作用很简单,就是将指定的文本进行输出。因此,整个命令的功能是,如果 test1.txt 有 N 个空白行,那么执行此命令会输出 N 个 Blank line |
| bunzip2 | 解压 .bz2 文件 | bunzip2 file1.bz2 #解压一个叫做 “file1.bz2” 文件 |
| bzip2 | 将文件(夹)压缩为压缩 .bz2 文件 | bzip2 file1 #将一个叫做 “file1” 的文件(夹)压缩为 file1.bz2 |
| cat | 文本处理,查看文件内容,可以显示或追加文本内容 | cat file1 #从第一个字节开始正向查看file1文件的内容 cat file1 | command( sed, grep, awk, grep, etc…) > result.txt 合并一个文件的详细说明文本,并将简介写入一个新文件中 cat file1 | command( sed, grep, awk, grep, etc…) >> result.txt 合并一个文件的详细说明文本,并将简介写入一个已有的文件中 cat example.txt | awk 'NR%2==1' #删除example.txt文件中的所有偶数行 |
| cd | 进入、切换目录 | cd /home #进入 '/ home' 目录' cd .. #返回上一级目录 cd ../.. #返回上两级目录 cd #进入个人的主目录 cd ~user1 #进入个人的主目录 cd - #返回上次所在的目录 |
| chgrp | 改变文件的群组 | chgrp group1 file1 #改变file1的群组为group1 |
| chmod | 改变文件或目录的读写权限 | chmod ugo+rwx directory1 #设置directory1目录的所有人(u)、群组(g)以及其他人(o)以读(r )、写(w)和执行(x)的权限 chmod go-rwx directory1 #删除群组(g)与其他人(o)对directory1目录的读写执行权限 |
| chown | 改变文件或目录的所有人属性 | chown user1 file1 #改变一个文件的所有人属性 chown -R user1 directory1 #改变一个目录的所有人属性并同时改变改目录下所有文件的属性 chown user1:group1 file1 #改变一个文件的所有人和群组属性 chmod u+s /bin/file1 #设置一个二进制文件的 SUID 位 - 运行该文件的用户也被赋予和所有者同样的权限 chmod u-s /bin/file1 #禁用一个二进制文件的 SUID位 chmod g+s /home/public #设置一个目录的SGID 位 - 类似SUID ,不过这是针对目录的 chmod g-s /home/public #禁用一个目录的 SGID 位 chmod o+t /home/public #设置一个文件的 STIKY 位 - 只允许合法所有人删除文件 chmod o-t /home/public #禁用一个目录的 STIKY 位 文件的特殊属性 使用 "+" 设置权限,使用 "-" 用于取消 |
| comm | 文件删除处理 | comm -1 file1 file2 #比较两个文件的内容只删除 'file1' 所包含的内容 comm -2 file1 file2 #比较两个文件的内容只删除 'file2' 所包含的内容 comm -3 file1 file2 #比较两个文件的内容只删除两个文件共有的部分 |
| cp | 复制文件或目录 | cp file1 file2 #复制 file1 文件并命名为 file2 cp dir/* . #复制一个dir目录下的所有文件到当前工作目录 cp -a /tmp/dir1 . #复制 /tmp 路径下的一个 dir1 目录到当前工作目录 cp -a dir1 dir2 #复制 dir1目录并命名为 dir2 |
| df | 查看分区列表 | df -h #显示已经挂载的分区列表 |
| dos2unix | 编码格式转换,将文本文件的格式从MSDOS转换成UNIX | dos2unix filedos.txt fileunix.txt #将一个文本文件的格式从MSDOS转换成UNIX |
| du | 估算目录已经使用的磁盘空间 | du -sh dir1 #估算目录 “dir1” 已经使用的磁盘空间 |
| echo | 文本打印输出 | echo a b c | awk '{print $1}' #查看一行第一栏 echo a b c | awk '{print $1,$3}' #查看一行的第一和第三栏 |
| find | 文本搜索,查找处理 | find / -name file1 #从 '/' 开始进入根文件系统搜索文件和目录 find / -user user1 #搜索属于用户 'user1' 的文件和目录 find /home/user1 -name *.bin #在目录 '/ home/user1' 中搜索带有'.bin' 结尾的文件 find /usr/bin -type f -atime +100 #搜索在过去100天内未被使用过的执行文件 find /usr/bin -type f -mtime -10 #搜索在10天内被创建或者修改过的文件 find / -name *.rpm -exec chmod 755 '{}' \; #搜索以 '.rpm' 结尾的文件并定义其权限 find / -xdev -name *.rpm #搜索以 '.rpm' 结尾的文件,忽略光驱、捷盘等可移动设备find /home/user1 -name '*.txt' | xargs cp -av --target-directory=/home/backup/ --parents #从目录 /home/user1 查找并复制所有以 '.txt' 结尾的文件到另一个目录 /home/backup find /var/log -name '*.log' | tar cv --files-from=- | bzip2 > log.tar.bz2 #从 /var/log 目录查找所有以 '.log' 结尾的文件并做成一个bzip包 |
| gunzip | 解压 .gz 文件 | gunzip file1.gz #解压一个叫做 file1.gz 的文件 |
| grep | 文本查找处理 | grep Aug /var/log/messages #在文件 '/var/log/messages'中查找关键词"Aug" grep ^Aug /var/log/messages #在文件 '/var/log/messages'中查找以"Aug"开始的词汇 grep [0-9] /var/log/messages #选择 '/var/log/messages' 文件中所有包含数字的行 grep Aug -R /var/log/* #在目录 '/var/log' 及随后的目录中搜索字符串"Aug" |
| gzip | 压缩文件或目录,将文件或文件夹压缩为 .gz 格式压缩包 | gzip file1 #压缩一个叫做 'file1'的文件 gzip -9 file1 #最大程度压缩 |
| head | 查看文件内容 | head -2 file1 #查看 file1 文件的前两行 |
| less | 查看文件内容,类似 more 命令,但它允许在文件中和正向操作一样反向操作 | less file1 #查看 file1 文件内容 |
| ls | 查看目录中的文件 | ls -a #显示隐藏文件 ls -l #显示文件和目录的详细资料 ls *[0-9]* #显示包含数字的文件名和目录名 |
| ln | 为文件或目录创建物理链接或软链接 | ln -s file1 lnk1 #创建一个指向文件或目录的软链接 ln file1 lnk1 #创建一个指向文件或目录的物理链接 |
| mkdir | 创建目录 | mkdir dir1 #创建一个名子为 “dir1” 的目录 mkdir dir1 dir2 #同时创建 dir1、dir2 两个目录 mkdir -p /tmp/dir1/dir2 #创建一个目录树 |
| more | 查看一个长文件的内容 | more file1 #查看file1内容 |
| mv | 重命名/移动 一个目录 | mv dir1 new_dir #将 dir1 目录重命名new_dir目录 |
| paste | 文件合并处理 | paste file1 file2 #合并两个文件或两栏的内容 paste -d '+' file1 file2 #合并两个文件或两栏的内容,中间用"+"区分 |
| passwd | 修改密码 | passwd user1 #修改用户 user1 的密码 |
| pwd | 显示工作路径 | pwd |
| rm | 删除文件或目录 | rm -f file1 #删除一个叫做 'file1' 的文件' rmdir dir1 #删除一个叫做 'dir1' 的目录' rm -rf dir1 #删除一个叫做 'dir1' 的目录并同时删除其内容 rm -rf dir1 dir2 #同时删除两个目录及它们的内容 |
| rpm | RPM 包 - (Fedora, Redhat及类似系统) | rpm -ivh package.rpm #安装一个rpm包 rpm -ivh --nodeeps package.rpm #安装一个rpm包而忽略依赖关系警告 rpm -U package.rpm #更新一个rpm包但不改变其配置文件 rpm -F package.rpm #更新一个确定已经安装的rpm包 rpm -e package_name.rpm #删除一个rpm包 rpm -qa #显示系统中所有已经安装的rpm包 |
| sed | 文本替换处理 | sed 's/stringa1/stringa2/g' example.txt 将example.txt文件中的 "string1" 替换成 "string2" sed '/^$/d' example.txt #从example.txt文件中删除所有空白行 sed '/ *#/d; /^$/d' example.txt #从example.txt文件中删除所有注释和空白行 echo 'esempio' | tr '[:lower:]' '[:upper:]' #合并上下单元格内容 sed -e '1d' result.txt #从文件example.txt 中排除第一行 sed -n '/stringa1/p' #查看只包含词汇 "string1"的行 sed -e 's/ *$//' example.txt #删除每一行最后的空白字符 sed -e 's/stringa1//g' example.txt 从文档中只删除词汇 "string1" 并保留剩余全部 sed -n '1,5p;5q' example.txt #查看从第一行到第5行内容 sed -n '5p;5q' example.txt #查看第5行 sed -e 's/00*/0/g' example.txt #用单个零替换多个零 |
| sort | 文本排序处理 | sort file1 file2 #排序两个文件的内容 sort file1 file2 | uniq #取出两个文件的并集(重复的行只保留一份) sort file1 file2 | uniq -u #删除交集,留下其他的行 sort file1 file2 | uniq -d #取出两个文件的交集(只留下同时存在于两个文件中的文件) |
| tac | 查看文件的内容 | tac file1 #从最后一个字节开始反向查看file1文件内容 |
| tail | 查看文件内容 | tail -2 file1 #查看file1文件的最后两行 tail -f /var/log/messages #实时查看被添加到 /var/log/ 路径下的 messages 文件的内容 |
| tar | 压缩或解压 .tar 文件 | tar -cvf archive.tar file1 #创建一个非压缩的 tarball tar -cvf archive.tar file1 file2 dir1 #创建一个包含了 'file1', 'file2' 以及 'dir1'的档案文件 tar -tf archive.tar #显示一个包中的内容 tar -xvf archive.tar #释放一个包 tar -xvf archive.tar -C /tmp #将压缩包释放到 /tmp目录下 tar -cvfj archive.tar.bz2 dir1 #创建一个bzip2格式的压缩包 tar -jxvf archive.tar.bz2 #解压一个bzip2格式的压缩包 tar -cvfz archive.tar.gz dir1 #创建一个gzip格式的压缩包 tar -zxvf archive.tar.gz #解压一个gzip格式的压缩包 |
| touch | 新建空白文件或修改文件 | touch test1 #新建一个名为 test1 的空白文件 touch -t 0712250000 file1 #修改一个文件或目录的时间戳 - (YYMMDDhhmm) |
| tree | 显示文件和目录由根目录开始的树形结构 | tree #显示文件和目录由根目录开始的树形结构(1) lstree #显示文件和目录由根目录开始的树形结构(2) |
| unix2dos | 将文件的编码文件的格式从UNIX转换成MSDOS | unix2dos fileunix.txt filedos.txt #将一个文本文件的格式从UNIX转换成MSDOS |
| unzip | 解压 .zip 格式压缩包 | unzip file1.zip #解压一个zip格式压缩包 |
| vim | vim 编辑器开启编辑命令,可简写为 vi | vi test1 #新建 test1 文件并开始编辑,按键 i 进入编辑模式,按键 Esc 并输入 :wq 保存并退出,不保存则输入 :q |
| whereis | 显示一个二进制文件、源码或man的位置 | whereis gcc |
| which | 显示一个二进制文件或可执行文件的完整路径 | which gcc |
| yum | YUM 软件包升级器 - (Fedora, RedHat及类似系统) | yum install package_name #下载并安装一个rpm包 yum localinstall package_name.rpm #将安装一个rpm包,使用你自己的软件仓库为你解决所有依赖关系 yum update package_name.rpm #更新当前系统中所有安装的rpm包 yum update package_name #更新一个rpm包 yum remove package_name #删除一个rpm包 yum list #列出当前系统中安装的所有包 yum search package_name #在rpm仓库中搜寻软件包 yum clean packages #清理rpm缓存删除下载的包 yum clean headers #删除所有头文件 yum clean all #删除所有缓存的包和头文件 |
| zip | 创建 .zip 格式的压缩包 | zip file1.zip file1 #将 file1 创建为一个 file1.zip 的压缩包 zip -r file1.zip file1 file2 dir1 #将几个文件和目录同时压缩成一个zip格式的压缩包 |
3. Slurm 作业管理系统
共享计算服务器使用 Slurm 作业管理系统, cpu64c 队列每个节点64核,不按核计费。单核心对应 1GB 内存,若单核心使用内存超过 1GB ,将导致内存溢出,作业进程终止。
作业管理系统常用命令如下:
| 命令 | 功能介绍 | 常用命令例子 |
| sinfo | 显示系统资源使用情况 | sinfo |
| squeue | 显示作业状态 | squeue |
| srun | 用于交互式作业提交 | srun -N 1 -n 10 hostname |
| sbatch | 用于批处理作业提交 | sbatch -n 64 01-Sop.sh |
| salloc | 用于分配模式作业提交 | salloc -p cpu64c |
| scancel | 用于取消已提交的作业 | scancel JOBID |
| scontrol | 用于查询节点信息或正在运行的作业信息 | scontrol show job JOBID |
| sacct | 用于查看历史作业信息 | sacct -u xxx -S 2023-02-02 -E 2023-02-04 --field=jobid,partition,jobname,user,nnodes,start,end,elapsed,state |
3.1 sinfo 查看系统资源
sinfo 得到的结果是当前账号可使用的队列资源信息,如图所示:

其中,
第一列 PARTITION 是队列名;
第二列 AVAIL 是队列可用情况,如果显示 up 则是可用状态,如果显示 inact 则是不可用状态;
第三列 TIMELIMIT 是作业运行时间限制,默认是 infinite 没有限制;
第四列 NODES 是节点数;
第五列 STATE 是节点状态, idle 是空闲节点,alloc 是已被占用节点,comp 是正在释放资源的节点,其他状态的节点都不可用;
第六列 NODELIST 是节点列表。
sinfo 的常用命令选项:
| 命令示例 | 功能 |
| sinfo -n xxx | 指定显示节点 xxx 的使用情况 |
| sinfo -p cpu64c | 指定显示队列 cpu64c 的情况 |
其他选项可以通过 sinfo --help 查询。
3.2 squeue 查看作业状态
squeue 得到的结果是当前帐号的作业运行状态,如果 squeue 没有作业信息,则说明作业已退出。具体事例见下图:

其中,
第一列 JOBID 是作业号,作业号是唯一的;
第二列 PARATITION 是作业运行使用的队列名;
第三列 NAME 是作业名;
第四列 USER 是账号名;
第五列 ST 是作业状态,R 表示正常运行,PD 表示在排队,CG 表示正在退出,S 是管理员暂时挂起;
第六列 TIME 是作业运行时间;
第七列 NODES 是作业使用的节点数;
第八列 NODELIST(REASON) 对于运行作业( R 状态)显示作业是用的节点列表,对于排队作业( PD 状态),显示排队原因。
squeue 的常用命令选项:
| 命令示例 | 功能 |
| squeue -j 60 | 查看作业号为 60 的作业信息 |
| squeue -u xxx | 查看账号为 xxx 的作业信息 |
| squeue -p cpu64c | 查看提交到 cpu64c 队列的作业信息 |
| squeue -w xxx | 查看使用到 xxx 节点的作业信息 |
其他选项可以通过 squeue --help 命令查看。
3.3 srun 交互式提交作业
srun [options] program 命令属于交互式提交作业,有屏幕输出,但容易受网络波动影响,断网或关闭窗口会导致作业中断。
srun -p cpu64c -w xxx -n 64 -t 20 A.exe
交互式提交 A.exe 程序,如果不关心节点和时间限制,可以简写成 srun -p cpu64c -n 64 A.exe
其中,
-p cpu64c 指定提交作业到 cpu64c 队列;
-w xxx 指定使用节点 xxx ;
-n 64 指定进程数为 64 ,共享微型计算服务器 cpu64c 队列每一个节点64核;
-t 20 指定作业运行时间限制为20分钟;
srun 的一些常用命令选项:
| 参数选项 | 功能 |
| -N 1 | 指定节点数为1 |
| -n 1 | 指定进程数为1 |
| -c 64 | 指定每个进程(任务)使用的 CPU 核数为64 |
| -p cpu64c | 指定提交作业到 cpu64c 队列 |
| -w xxx | 指定提交作业到 xxx 节点 |
| -x xxx | 排除使用 xxx 节点 |
| -o out.log | 指定标准输出到 out.log 文件 |
| -e err.log | 指定重定向错误输出到 err.log 文件 |
| -J JOBNAME | 指定作业名为 JOBNAME |
| -t 20 | 限制运行20分钟 |
srun 的其他选项可通过 srun --help 查看。
sbatch 后台提交作业
sbatch 一般情况下与 srun 一起提交作业到后台,需要将 srun 写到脚本中,再用 sbatch 提交脚本,这种方式不受本地网络波动影响,提交作业后可以关闭本地电脑,sbatch 命令没有屏幕输出,默认输出日志为提交目录下的 slurm-xxx.out 可以使用 tail -f slurm-xxx.out 实时查看日志,其中 xxx 为作业号。
sbatch 命令示例1 (64个进程提交A.exe程序)
编写脚本 job1.sh,内容如下:
#!/bin/bash
#SBATCH -N 1
#SBATCH -n 64
环境变量
srun -n 64 A.exe然后再命令行执行 sbatch -p cpu64c job1.sh 提交作业。
脚本中的开头#!/bin/bash 是 bash 脚本的固定格式。从脚本的形式可以看出,提交的脚本是一个 shell 脚本,因此常用的 shell 脚本语法都可以使用。作业开始运行后,在提交目录会自动生成一个 slurm-xxx.out 日志文件,其中 xxx 表示作业号。
sbatch 命令示例2 (指定2个进程,每个进程32个 cpu 核提交 A.exe,限制运行60分钟)
编写脚本 job2.sh,内容如下:
#!/bin/bash
#SBATCH -N 1
#SBATCH -n 2
#SBATCH -c 32
#SBATCH -t 60
srun -n 4 A.exe然后在命令行执行 abatch -p cpu64c job2.sh 就可以提交作业。
其中,#SBATCH 注释行是 slurm 定义的作业执行方式说明,一些需要通过命令行指定的设置可以通过这些说明写在脚本里,避免了每次提交作业写很长的命令行。
sbatch 的一些常用命令选项基本与 srun 的相同,具体可以通过 sbatch --help 查阅。
3.5 salloc 分配模式作业提交
salloc 命令用于申请节点资源,一般用法如下:
1、执行 salloc -p cpu64c ;
2、执行 squeue 查看分配到的节点资源,比如分配到 62;
3、执行 ssh 62 登录到所分配到的节点;
4、登陆节点后可以执行需要的提交命令或程序;
5、作业结束后,执行 scancel JOBID 释放分配模式作业的节点资源。
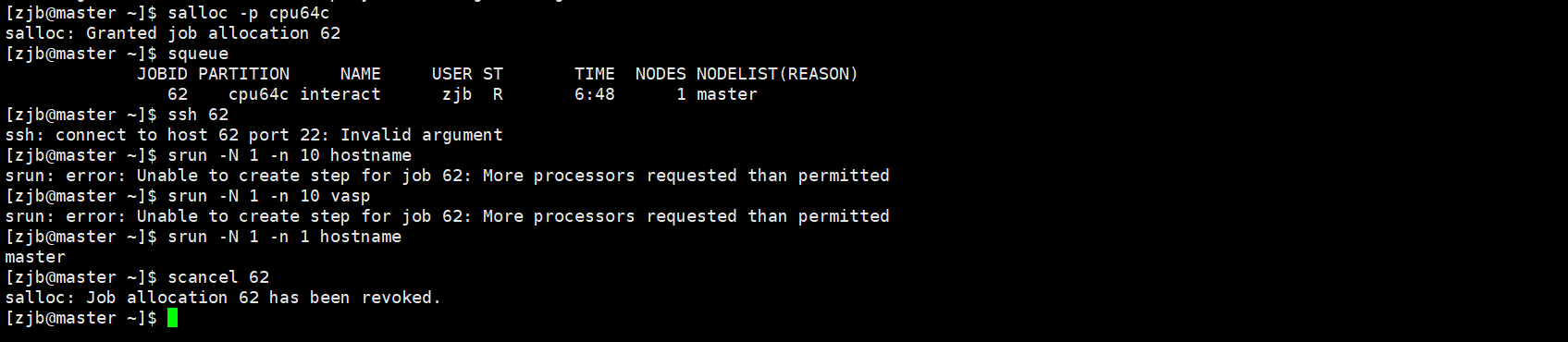
3.6 scancel 取消已提交的作业
scancel 可以取消正在运行或排队的作业。
scancel 的一些常用命令示例:
| 命令示例 | 功能 |
| scancel 62 | 取消作业号为62的作业 |
| scancel -n vasp_SOp | 取消作业名为 vasp_SOp 的作业 |
| scancel -p cpu64c | 取消提交到 cpu64c 队列的作业 |
| scancel -t PENDING | 取消正在排队的作业 |
| scancel -w xxx | 取消运行在 xxx 节点上的作业 |
scancel 的其他命令选项可以通过 scancel --help 查阅。
3.7 scontrol 查看正在运行的作业信息
scontrol 命令可以查看正在运行的作业详情,比如提交目录、提交脚本、使用核数情况等,但对已退出的作业无效。
scontrol 的常用示例:
scontrol show job 62查看作业号为62的作业详情。
scontrol 的其他参数选项可以通过 scontrol --help 查看。
3.8 sacct 查看历史作业信息
sacct 命令可以查看历史作业的起止时间、结束状态、作业号、作业名、使用的节点数、节点列表、运行时间等。
sacct 的常用命令示例:
sacct -u test -S 2023-02-02 -E now --field=jobid,partition,jobname,user,nnodes,nodelist,start,end,elapsed,state其中,
-u test 是指查看 test 账号的历史作业信息,
-S 是开始查询时间,
-E 是截止查询时间,
--field 定义了输出的格式,jobid 是指作业号,partition 是指提交队列,user 是指账户名,nnodes 是指节点数,nodelist 是指节点列表,start 是指开始运行时间,end 是指作业退出时间,elapsed 是指运行时间,state 是指作业结束状态。
sacct 的其他参数选项可以通过 sacct --help 查看。
4. 编译器
共享微型计算服务器已配置 GNU和 Intel 编译器,支持 C、C++、Fortran77 和 Fortran90 语言程序的开发,支持 MPI 并行编程模式,与 OpenMP 不同, OpenMP 为共享内存方式,只能单点并行;MPI 是分布式内存并行,支持跨节点并行。
4.1 Intel 编译器
共享微型机算服务器已经加载 Intel 编译环境,编译器安装在 /opt/intel/ 路径下。
通过 “which” 命令可以查找所在路径,例如 “which icc”;通过 “icc -v” 命令可以查询 icc 的版本。Intel 编译器的详细命令行调用则可以用 ”icc --help” 获得。
用户经常需要使用 MKL 库,通过命令 echo $MKLROOT 可以查看 MKLROOT 环境变量确认 MKL 库的位置。
4.2 GCC 编译器
共享微型机算服务器默认的 GNU 编译器版本是4.8.5。
4.3 MPI 编译环境
共享微型机算服务器已加载 MPI 编译环境。
温馨提示:
资源均系网络采集及热心网友分享,仅供个人学习,未获正版授权,不得商用或将商业程序所计算得出结果等用于Paper文章发表,否则由此引起的纠纷请自己解决,如的确需要使用请购买正版授权或其他合法渠道取得资格使用,请自行解决版权问题。
重要守则:
严禁用户搭建非法赌博、色情、跑分、破解VIP资源等服务网站应用,不得运行挖矿程序。如发现删除账号禁用资源,情节严重者报警处理!

Comments NOTHING